UEM AWS Native Migration in Action
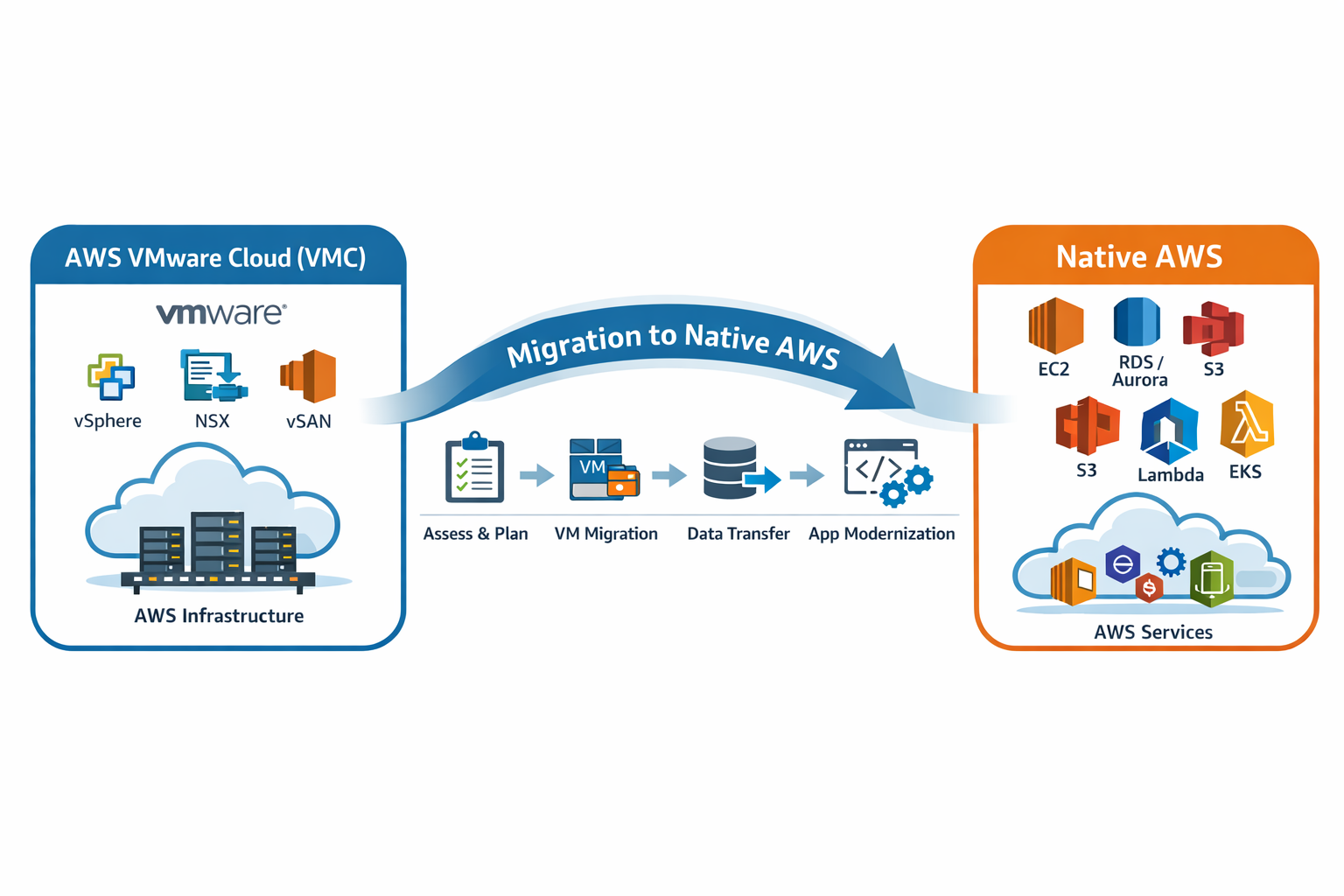
This article is part 3 of the series Migrating UEM from AWS VMC to Native AWS
Challenge
Following the decision to transition the UEM SaaS offering to a fully native AWS architecture, we undertook one of the largest platform modernization and migration efforts. The challenge was not just migrating—it was automating, rebuilding, and operating the platform at unprecedented scale.
Migrating the UEM SaaS platform to AWS native meant tackling 1,200+ production environments and the supporting services across 11 datacenters, all while ensuring minimal disruption to customers. In parallel, 4 non-production datacenters had to be migrated to validate automation and test at scale, ensuring every step was reliable before touching live workloads.
At this scale, even a 1% failure rate could impact dozens of customer environments, making reliability, repeatability, and automation non-negotiable. Success required re-architecting the platform with infrastructure-as-code, end-to-end automation, and AWS-native services. The entire transition had to be executed in a controlled, measurable, low-risk way to safeguard every customer environment.
Migration Plan
To migrate the UEM SaaS platform at scale, we structured our approach around five key pillars:
- Modernization
- Infrastructure Deployment
- Automation Readiness
- Security
- Observability
Each pillar focused on building a fully automated, cloud-native, and secure platform. The table below presents a comprehensive overview of our approach, emphasizing the critical actions executed throughout the migration process.
| Pillar | What We Did | Goal |
|---|---|---|
| Modernization | • FSx replaced legacy Windows shares • AWS Managed AD adoption • RDS for SQL server • ElastiCache for Memcached • AWCM containerized and deployed on ECS Fargate | 100% cloud-native, scalable services |
| Infrastructure Deployment | • Custom AMIs built for standardized deployments • Terraform automation for all deployments • IaC for repeatable provisioning | No manual touchpoints — all deployments via code |
| Automation Readiness | • Multi-platform support (VMC + AWS) • Day-2 operations seamless | Zero gaps during cross-platform migration |
| Security | • Custom security groups for each service • Rapid7 → WIZ migration | Security embedded from day one |
| Observability | • Full metrics & monitoring • Continuous dashboard updates | Full visibility across workloads |
Engineering Hurdles
There were countless challenges we had to tackle during this migration, but some of the most complex and high-scale tasks included:
- Re-writing automation for UEM to transition from self-managed services running on AWS VMC to AWS-managed services such as EC2 and RDS SQL Server, while simultaneously designing robust rollback strategies to move fast without sacrificing safety.
- Supporting dual-stacks as we simultaneously maintained existing customer environments in VMC and began deploying and maintaining new environments in native AWS. This had to be done without missing a beat on Day-2 operations like scaling, patching, upgrading, and UEM lifecycle management.
- Moving terabytes of data from our VSAN Windows shares to Amazon FSx. The process could run for days and each file had to be verified before we could safely reconfigure thousands of environments—because at this scale. Mistakes weren’t an option.
Each of these hurdles pushed our engineering limits—and overcoming them is what made the migration run at scale.
Migration in Action
Before we could kick off the migration, we had to lay the foundation—and it was massive. We built a robust infrastructure that could handle scale, performance, and reliability at every step. Here’s a glimpse of what we brought to life:
- 100+ RDS SQL Servers
- 120+ Elasticache Clusters
- 250+ ETL Clusters
- 4,000+ EC2 Instances
Next, the migration unfolded in two high-impact phases
- Phase 1 – UAT: We moved ~400 UAT environments to native AWS in just 6–7 weeks—smooth, fast, and precise.
- Phase 2 – Production: The real challenge. 850+ PROD environments had to be migrated, all while coordinating timelines with customers and juggling requests. Despite the complexity, we pulled it off in a record of 9 weeks.
While migrating customer environments remained our top priority, we deployed 4 non-production datacenters —all in parallel and without a hitch. From infrastructure to execution, this migration was big, bold, and lightning-fast—a true showcase of planning, teamwork, and automation.
A Few Engineering Learnings
- At our scale, instance type shortages in some regions were inevitable. We built automation to dynamically select equivalent instances, allowing migrations to proceed without impacting performance or cost.
- We adopted a backup-to-multiple-files strategy for large databases, striping backups across several files instead of a single file. This improved backup and restore performance while distributing I/O more efficiently.
- FSx data migrations required careful handling due to deduplication behavior and the large number of small files. Leveraging multithreaded robocopy for bulk transfer, followed by DataSync for validation and incremental updates, proved to be the most effective approach.
Outcome in Focus
After overcoming enormous engineering hurdles, the results spoke for themselves.
- Effortless, lightning-fast migrations: Single-click automation allowed us to move hundreds of environments at scale without breaking a sweat.
- Provisioning at warp speed: Leveraging Infrastructure as Code turned complex service setup into a repeatable, near-instant process, every time.
- More power, zero extra cost: By enhancing infrastructure and adopting managed services, we deliver higher performance and reliability while keeping costs on par with our VMC deployment.
These outcomes didn’t just demonstrate technical excellence—they showed what’s possible when automation, planning, and engineering at scale to come together.